Recommender systems - Neural Collaborative Filtering
Demo



Download dependencies and run tensorboard in the background:
!pip install tensorflow lightfm pandas
%load_ext tensorboard
!tensorboard --logdir 2020-09-11-neural_collaborative_filter/logs &

# collapse
for dataset in ["test", "train"]:
data[dataset] = (data[dataset].toarray() > 0).astype("int8")
# Make the ratings binary
print("Interaction matrix:")
print(data["train"][:10, :10])
print("\nRatings:")
unique_ratings = np.unique(data["train"])
print(unique_ratings)
from typing import List
def wide_to_long(wide: np.array, possible_ratings: List[int]) -> np.array:
"""Go from wide table to long.
:param wide: wide array with user-item interactions
:param possible_ratings: list of possible ratings that we may have."""
def _get_ratings(arr: np.array, rating: int) -> np.array:
"""Generate long array for the rating provided
:param arr: wide array with user-item interactions
:param rating: the rating that we are interested"""
idx = np.where(arr == rating)
return np.vstack(
(idx[0], idx[1], np.ones(idx[0].size, dtype="int8") * rating)
).T
long_arrays = []
for r in possible_ratings:
long_arrays.append(_get_ratings(wide, r))
return np.vstack(long_arrays)
long_train = wide_to_long(data["train"], unique_ratings)
df_train = pd.DataFrame(long_train, columns=["user_id", "item_id", "interaction"])
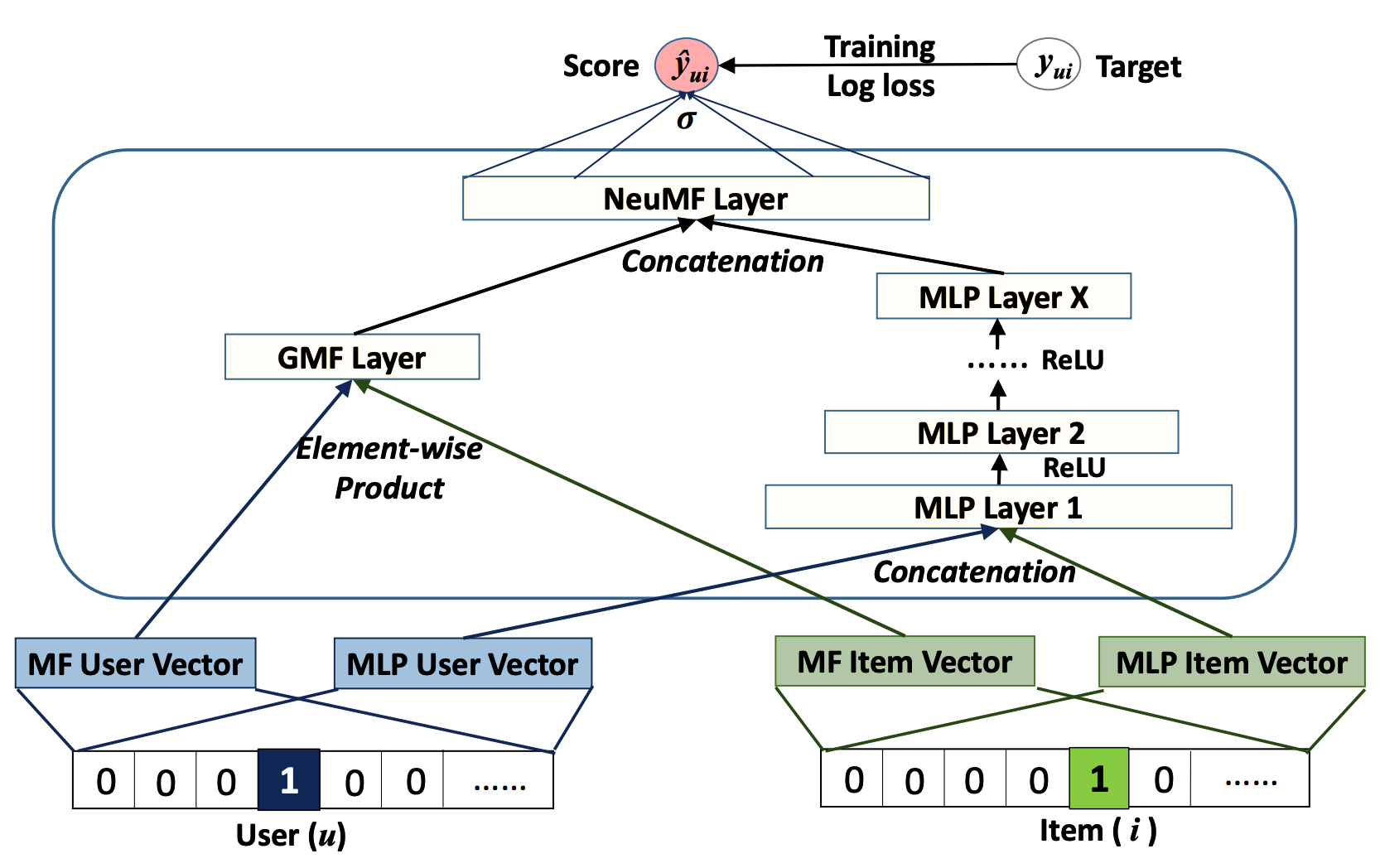
import tensorflow.keras as keras
from tensorflow.keras.layers import (
Concatenate,
Dense,
Embedding,
Flatten,
Input,
Multiply,
)
from tensorflow.keras.models import Model
from tensorflow.keras.regularizers import l2
def create_ncf(
number_of_users: int,
number_of_items: int,
latent_dim_mf: int = 4,
latent_dim_mlp: int = 32,
reg_mf: int = 0,
reg_mlp: int = 0.01,
dense_layers: List[int] = [8, 4],
reg_layers: List[int] = [0.01, 0.01],
activation_dense: str = "relu",
) -> keras.Model:
# input layer
user = Input(shape=(), dtype="int32", name="user_id")
item = Input(shape=(), dtype="int32", name="item_id")
# embedding layers
mf_user_embedding = Embedding(
input_dim=number_of_users,
output_dim=latent_dim_mf,
name="mf_user_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mf),
input_length=1,
)
mf_item_embedding = Embedding(
input_dim=number_of_items,
output_dim=latent_dim_mf,
name="mf_item_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mf),
input_length=1,
)
mlp_user_embedding = Embedding(
input_dim=number_of_users,
output_dim=latent_dim_mlp,
name="mlp_user_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mlp),
input_length=1,
)
mlp_item_embedding = Embedding(
input_dim=number_of_items,
output_dim=latent_dim_mlp,
name="mlp_item_embedding",
embeddings_initializer="RandomNormal",
embeddings_regularizer=l2(reg_mlp),
input_length=1,
)
# MF vector
mf_user_latent = Flatten()(mf_user_embedding(user))
mf_item_latent = Flatten()(mf_item_embedding(item))
mf_cat_latent = Multiply()([mf_user_latent, mf_item_latent])
# MLP vector
mlp_user_latent = Flatten()(mlp_user_embedding(user))
mlp_item_latent = Flatten()(mlp_item_embedding(item))
mlp_cat_latent = Concatenate()([mlp_user_latent, mlp_item_latent])
mlp_vector = mlp_cat_latent
# build dense layers for model
for i in range(len(dense_layers)):
layer = Dense(
dense_layers[i],
activity_regularizer=l2(reg_layers[i]),
activation=activation_dense,
name="layer%d" % i,
)
mlp_vector = layer(mlp_vector)
predict_layer = Concatenate()([mf_cat_latent, mlp_vector])
result = Dense(
1, activation="sigmoid", kernel_initializer="lecun_uniform", name="interaction"
)
output = result(predict_layer)
model = Model(
inputs=[user, item],
outputs=[output],
)
return model
# collapse
from tensorflow.keras.optimizers import Adam
n_users, n_items = data["train"].shape
ncf_model = create_ncf(n_users, n_items)
ncf_model.compile(
optimizer=Adam(),
loss="binary_crossentropy",
metrics=[
tf.keras.metrics.TruePositives(name="tp"),
tf.keras.metrics.FalsePositives(name="fp"),
tf.keras.metrics.TrueNegatives(name="tn"),
tf.keras.metrics.FalseNegatives(name="fn"),
tf.keras.metrics.BinaryAccuracy(name="accuracy"),
tf.keras.metrics.Precision(name="precision"),
tf.keras.metrics.Recall(name="recall"),
tf.keras.metrics.AUC(name="auc"),
],
)
ncf_model._name = "neural_collaborative_filtering"
ncf_model.summary()
def make_tf_dataset(
df: pd.DataFrame,
targets: List[str],
val_split: float = 0.1,
batch_size: int = 512,
seed=42,
):
"""Make TensorFlow dataset from Pandas DataFrame.
:param df: input DataFrame - only contains features and target(s)
:param targets: list of columns names corresponding to targets
:param val_split: fraction of the data that should be used for validation
:param batch_size: batch size for training
:param seed: random seed for shuffling data - `None` won't shuffle the data"""
n_val = round(df.shape[0] * val_split)
if seed:
# shuffle all the rows
x = df.sample(frac=1, random_state=seed).to_dict("series")
else:
x = df.to_dict("series")
y = dict()
for t in targets:
y[t] = x.pop(t)
ds = tf.data.Dataset.from_tensor_slices((x, y))
ds_val = ds.take(n_val).batch(batch_size)
ds_train = ds.skip(n_val).batch(batch_size)
return ds_train, ds_val
# create train and validation datasets
ds_train, ds_val = make_tf_dataset(df_train, ["interaction"])
%%time
# define logs and callbacks
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
early_stopping_callback = tf.keras.callbacks.EarlyStopping(
monitor="val_loss", patience=0
)
train_hist = ncf_model.fit(
ds_train,
validation_data=ds_val,
epochs=N_EPOCHS,
callbacks=[tensorboard_callback, early_stopping_callback],
verbose=1,
)
long_test = wide_to_long(data["train"], unique_ratings)
df_test = pd.DataFrame(long_test, columns=["user_id", "item_id", "interaction"])
ds_test, _ = make_tf_dataset(df_test, ["interaction"], val_split=0, seed=None)
%%time
ncf_predictions = ncf_model.predict(ds_test)
df_test["ncf_predictions"] = ncf_predictions
# collapse
data["ncf_predictions"] = df_test.pivot(
index="user_id", columns="item_id", values="ncf_predictions"
).values
print("Neural collaborative filtering predictions")
print(data["ncf_predictions"][:10, :4])
precision_ncf = tf.keras.metrics.Precision(top_k=TOP_K)
recall_ncf = tf.keras.metrics.Recall(top_k=TOP_K)
precision_ncf.update_state(data["test"], data["ncf_predictions"])
recall_ncf.update_state(data["test"], data["ncf_predictions"])
print(
f"At K = {TOP_K}, we have a precision of {precision_ncf.result().numpy():.5f}",
"and a recall of {recall_ncf.result().numpy():.5f}",
)
%%time
# LightFM model
def norm(x: float) -> float:
"""Normalize vector"""
return (x - np.min(x)) / np.ptp(x)
lightfm_model = LightFM(loss="warp")
lightfm_model.fit(sparse.coo_matrix(data["train"]), epochs=N_EPOCHS)
lightfm_predictions = lightfm_model.predict(
df_test["user_id"].values, df_test["item_id"].values
)
df_test["lightfm_predictions"] = lightfm_predictions
wide_predictions = df_test.pivot(
index="user_id", columns="item_id", values="lightfm_predictions"
).values
data["lightfm_predictions"] = norm(wide_predictions)
# compute the metrics
precision_lightfm = tf.keras.metrics.Precision(top_k=TOP_K)
recall_lightfm = tf.keras.metrics.Recall(top_k=TOP_K)
precision_lightfm.update_state(data["test"], data["lightfm_predictions"])
recall_lightfm.update_state(data["test"], data["lightfm_predictions"])
print(
f"At K = {TOP_K}, we have a precision of {precision_lightfm.result().numpy():.5f}",
"and a recall of {recall_lightfm.result().numpy():.5f}",
)